


Evan Kiefl
Table of Contents
I recently moved in with my girlfriend (Kourtney) who has a 6-month old puppy named Maple. She’s a sweet girl (the puppy), however she was born in the COVID era, and that comes with some behavioral challenges. The biggest problem is that she’s developed an unrealistic assumption that she can be with us 100% of the time. And when that unrealistic expectation is challenged by us leaving the apartment, she barks. Loudly. I wanted to create an application written in Python that monitors and responds to her barks.
By the end of this post, the program (which you have full, open-access to) will detect dog barks using PyAudio and make decisions on whether to praise or scold the dog based on its behavior. This is all done in real time. At this point, both praising and scolding means playing a pre-recorded voice of the owner that is either of positive or negative sentiment. The audio, statistics, and time of each bark, as well as statistics of owner responses are stored in a SQLite database. Finally, I’ll show some interactive plots of the results using Plotly.
Simple demo
It’s always good to start simple so I just searched for python live audio processing and found this blog post by Scott W Harden. In it, he posts a simple script that monitors in real-time the amplitude of the audio signal. I turned it into a class structure:
#! /usr/bin/env python
import numpy as np
import pyaudio
import argparse
CHUNK = 2**11
RATE = 44100
class LiveStream(object):
def __init__(self, args = argparse.Namespace()):
self.args = args
self.p = pyaudio.PyAudio()
self.stream = None
def start(self):
while True:
data = np.fromstring(self.stream.read(CHUNK), dtype=np.int16)
self.process_data(data)
def __enter__(self):
self.stream = self.p.open(
format = pyaudio.paInt16,
channels = 1,
rate = RATE,
input = True,
frames_per_buffer = CHUNK,
)
return self
def __exit__(self, exception_type, exception_value, traceback):
self.stream.stop_stream()
self.stream.close()
self.p.terminate()
def process_data(self, data):
peak=np.average(np.abs(data))*2
bars="#"*int(2000*peak/2**16)
print("%05d %s"%(peak,bars))
# uncomment to push highest amplitude frequency to stdout
#x = data
#w = np.fft.fft(x)
#freqs = np.fft.fftfreq(len(x))
#max_freq = abs(freqs[np.argmax(w)] * RATE)
#peak = max_freq
#bars="o"*int(4000*peak/2**16)
#print("%05d %s"%(peak,bars))
if __name__ == '__main__':
with LiveStream() as s:
s.start()
Here’s a demo:
Event detection
With a bare-bones script that demos a live output of audio amplitude and/or frequency, it was time to get serious: detecting events. I wanted to be able to detect events since in order to rationally respond to your dog, you need to be able to detect when it is barking.
Events are basically anomalies in the background noise, and so to detect events, we need to properly distinguish background from signal. To do this, I wrote a calibration method that runs at the start of the program. The premise is to wait until the audio signal reaches an equilibrium, and then measures the mean ($ \mu $) and standard deviation ($ \sigma $) of the signal strength. I consider equilibrium to be established by demanding that the coefficient of variation ($ \sigma/\mu $) is less than some threshold value, since a low coefficient of variation means a stable signal. The background mean and standard deviation that satisfied this constraint for equilibrium can then be used to distinguish signal from noise.
We can do some back of the envelope calculations to show that if the signal is drawn from a Normal distribution (a bell-shaped curve), there is a ~16% chance that any given datapoint in the signal will exceed 1 standard deviation about the mean ($\mu + \sigma$). That probability becomes ~2.5% that it will exceed 2 standard deviations ($\mu + 2\sigma$) and ~0.5% that it exceeds 3 standard deviations ($\mu + 3\sigma$). As a first step, I went ahead and wrote a detector that detects the start of an event whenever the signal exceeds 3 standard deviations, and the end of the event whenever it dips below 2 standard deviations. Here is a demo showing the efficacy of this approach:
From here on in, I started developing within a multi-file environment (the whole repo can be found here). To make everything accessible as possible, each code snippet and demo video will be followed by a hyperlink that brings you to the stage in the codebase from where the snippet or demo was taken.
Better event detection
As mentioned in the video, there are a lot of false-positives for the ends of events. In other words, many of my spoken sentences were being split up into multiple events, even when there was little or no break in my speaking rhythm. This was happening because the criterion for events ending was too simple, and based on a single audio frame (reminder: the event ends if the mean audio signal of an audio frame drops below $\mu + 2\sigma$, where $ \mu $ and $ \sigma $ are the mean and standard deviation of the background noise). This is problematic because each frame is only a couple of milliseconds. To more accurately depict the start and stop of events, I wanted to create criteria that spanned multiple frames.
In the above video, the program has just 1 state variable called in_event, and its possible values
are either True or False. Here is a flowchart of the transitions possible:
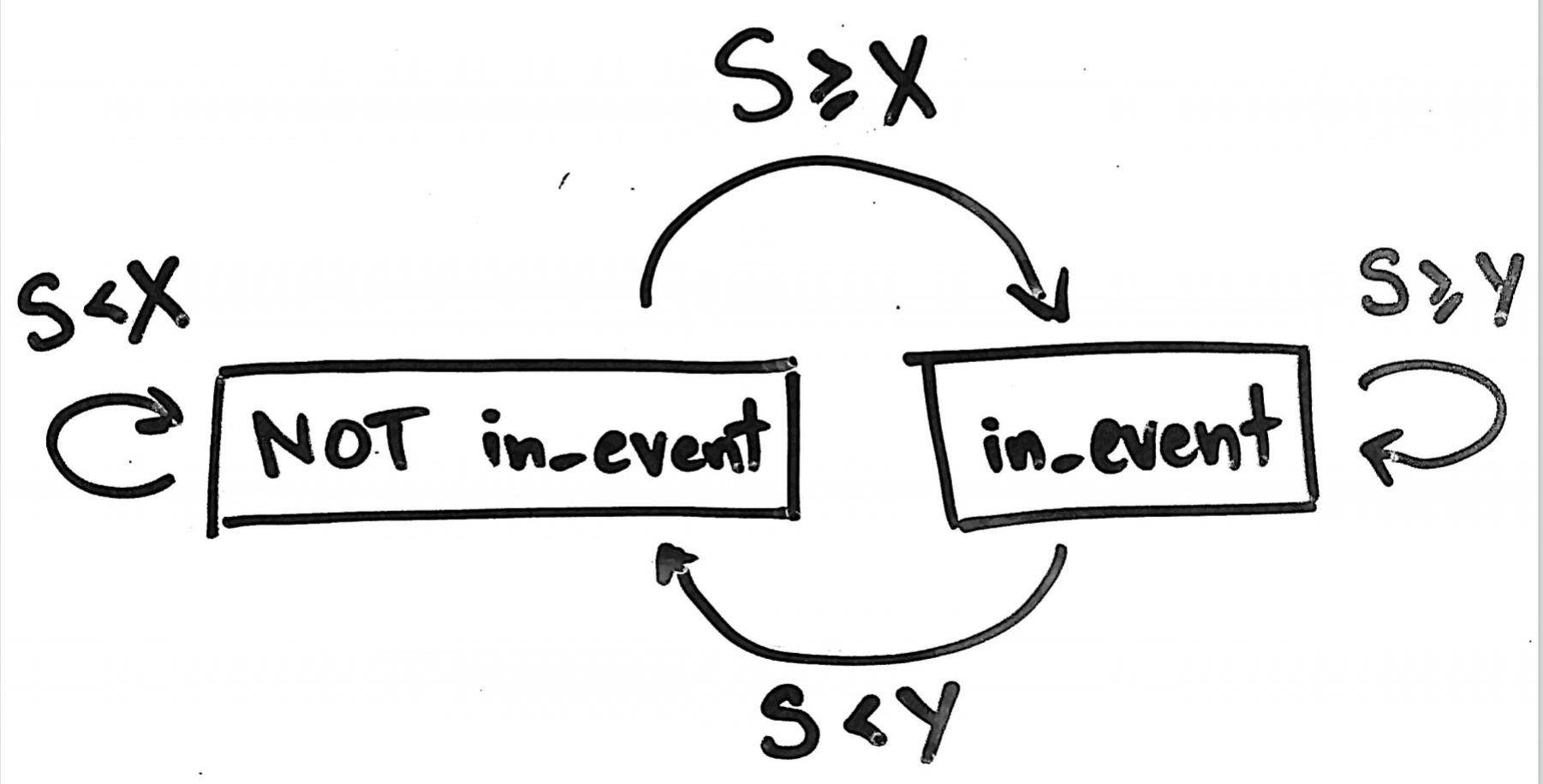
Soon we’ll see that making a more robust event detector inevitably complicates this simple picture.
Event start criterion
In the video, transitioning from in_event == False to in_event == True occurred whenever a frame
had a mean signal 3 standard deviations above the mean. Let’s call this threshold value $X$ for
convenience. My new criterion is that there must be $N$ consecutive frames that are all above
$X$. If $N$ consecutive frames all meet this threshold, then the event start is attributed to
the first frame in this frame sequence. Requiring consecutive frames to pass the threshold
effectively guards against false-positives when loud but short (~ millisecond) sounds are made,
which trigger an event. The stringency is thus controlled by $N$: the lower $N$ is, the more
false-positives in event starts you allow.
Programmatically, whenever a frame’s mean signal exceeds $X$ while in_event == False, a second
state variable in_on_transition is set to True. Whenever in_on_transition == True, it
basically means, “Ok, we’re not for sure in an event, but things are starting to get loud, and if
we stay in this state for long enough, we’ll for sure know we are in an event”. If
in_on_transition == True for $N$ consecutive frames, then the program is convinced it is
actually an event, so in_event is set to True and in_on_transition is returned to False. On
the other hand, if any frame fails to exceed $X$, in_on_transition is set to False and the
potential event is deemed not an event. To avoid clipping the start of the event because the
detector is busy making its mind up, whenever in_on_transition == True, the audio
frames are stored in a buffer and retroactively added to the event.
Event end criterion
Before, an event ended whenever a frame had a mean signal that dipped below 2 standard deviations above the mean ($\mu + 2\sigma$). Call this threshold $Y$ for convenience. My new method uses the same criterion, but rather than ending the event when this occurs, a countdown of $T$ seconds starts. If $T$ reaches 0, the event ends. But it is possible to “save” the event, if any frame during the countdown has a mean signal exceeding $X$ (the event start threshold). In this case, the event will continue until the next time the mean signal dips below $Y$. The countdown safeguards against against false-positives that end events because there was a momentary lapse in sound amplitude. The stringency is thus controlled by $T$: the lower $T$ is, the more false-positives in event ends you allow.
Programmatically, whenever a frame’s mean signal dips below $Y$ while in_event == True, a second
state variable in_off_transition is set to True. This starts a countdown. If any frame during
the countdown exceeds $X$, in_off_transition is set to False, and the event is given life
anew. But if no frames exceed $X$ during the countdown, the event is deemed to have finished, so
in_event is set to False and in_off_transition is returned to False.
With the implementation of these new criteria, here is the updated state logic visualized as a flow chart:
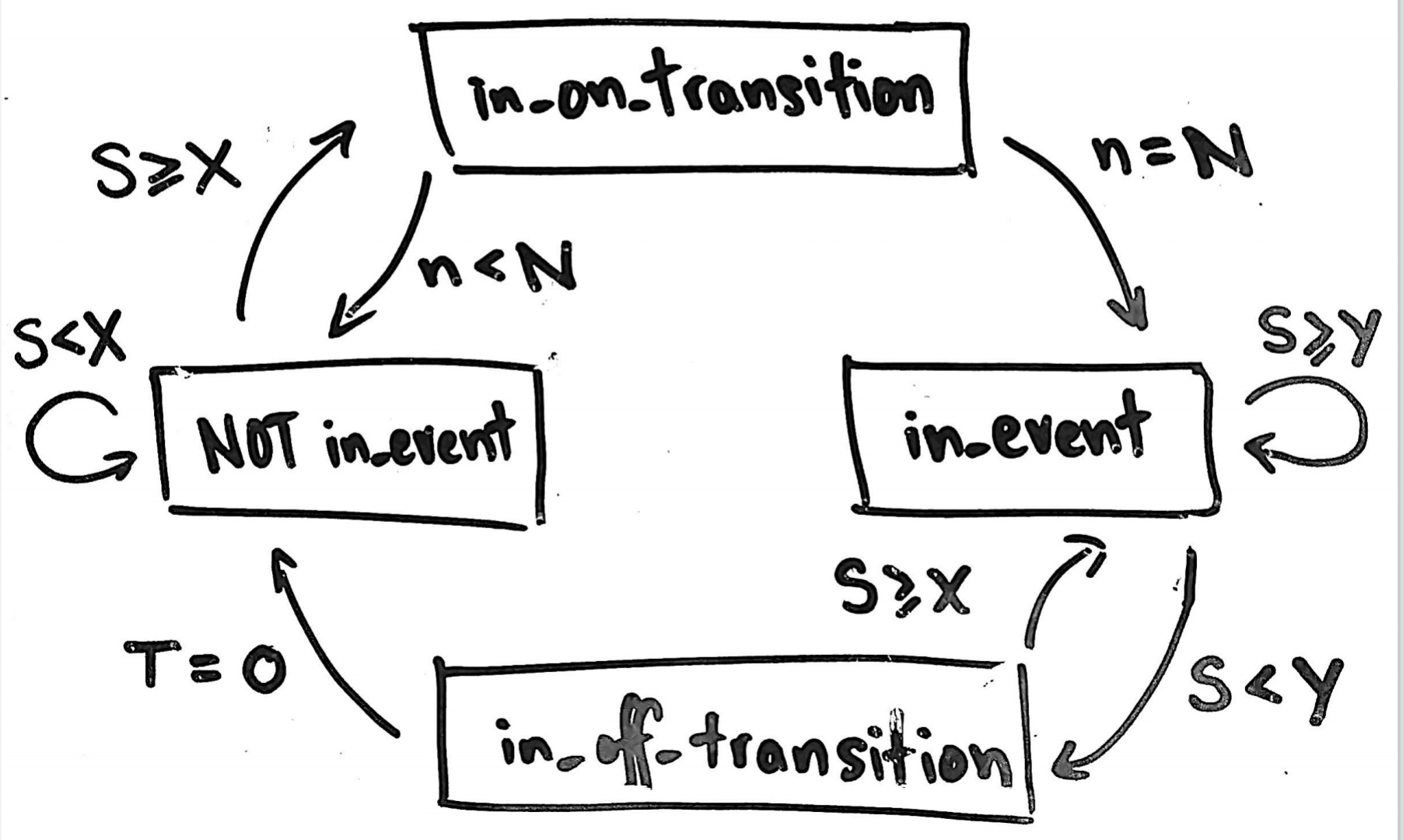
It’s a little more complicated, but there is a pleasant symmetry.
Results
Here is a demo of the new event detector.
Overall, I am happy with how it works and ready to move on.
A generic audio detector
I noticed at this point that nothing I have done so far has anything to do with dogs and barking.
Being noncommittal is a great quality in a codebase because it creates flexibility. For the
purpose of making this useful to anyone with their own applications, I created a well-polished
branch of the repository that can be used for generic audio event detection. I reorganized
everything into a single file, so after installing numpy and pyaudio, you are ready to rumble:
#! /usr/bin/env python
import numpy as np
import pyaudio
CHUNK = 2**11
RATE = 44100
def calc_power(data):
"""Calculate the power of a discrete time signal"""
return np.mean(np.abs(data))*2
class Stream(object):
def __init__(self):
self.p = pyaudio.PyAudio()
self._stream = self.p.open(
format = pyaudio.paInt16,
channels = 1,
rate = RATE,
input = True,
frames_per_buffer = CHUNK,
start = False, # To read from stream, self.stream.start_stream must be called
)
def __enter__(self):
if not self._stream.is_active():
self._stream.start_stream()
return self
def __exit__(self, exc_type, exc_val, traceback):
self._stream.stop_stream()
def close(self):
"""Close the stream gracefully"""
if self._stream.is_active():
self._stream.stop_stream()
self._stream.close()
self.p.terminate()
class Monitor(object):
def __init__(self, args = argparse.Namespace()):
self.args = args
self.dt = CHUNK/RATE # Time between each sample
# Calibration parameters
self.calibration_time = 3 # How many seconds is calibration window
self.calibration_threshold = 0.50 # Required ratio of std power to mean power
self.calibration_tries = 1 # Number of running windows tried until threshold is doubled
# Event detection parameters
self.event_start_threshold = 3 # standard deviations above background noise to start an event
self.event_end_threshold = 2 # standard deviations above background noise to end an event
self.seconds = 0.5
self.num_consecutive = 4
self.stream = None
self.background = None
self.background_std = None
self.detector = None
self.event_recs = {}
self.num_events = 0
def read_chunk(self):
"""Read a chunk from the stream and cast as a numpy array"""
return np.fromstring(self.stream._stream.read(CHUNK), dtype=np.int16)
def calibrate_background_noise(self):
"""Establish a background noise
Calculates moving windows of power. If the ratio between standard deviation and mean is less
than a threshold, signifying a constant level of noise, the mean power is chosen as the
background. Otherwise, it is tried again. If it fails too many times, the threshold is
increased and the process is repeated.
"""
stable = False
power_vals = []
# Number of chunks in running window based on self.calibration time
running_avg_domain = int(self.calibration_time / self.dt)
with self.stream:
tries = 0
while True:
for i in range(running_avg_domain):
power_vals.append(calc_power(self.read_chunk()))
# Test if threshold met
power_vals = np.array(power_vals)
if np.std(power_vals)/np.mean(power_vals) < self.calibration_threshold:
self.background = np.mean(power_vals)
self.background_std = np.std(power_vals)
return
# Threshold not met, try again
power_vals = []
tries += 1
if tries == self.calibration_tries:
# Max tries met--doubling calibration threshold
print(f"Calibration threshold not met after {tries} tries. Increasing threshold "
f"({self.calibration_threshold:.2f} --> {1.5*self.calibration_threshold:.2f})")
tries = 0
self.calibration_threshold *= 1.5
def setup(self):
self.stream = Stream()
self.calibrate_background_noise()
self.detector = Detector(
background_std = self.background_std,
background = self.background,
start_thresh = self.event_start_threshold,
end_thresh = self.event_end_threshold,
seconds = self.seconds,
num_consecutive = self.num_consecutive,
dt = self.dt,
)
self.wait_for_events()
def wait_for_events(self):
while True:
self.wait_for_event()
# Do anything you want here
def wait_for_event(self, log=True):
"""Waits for an event, records the event, and returns the event audio as numpy array"""
self.detector.reset()
with self.stream:
while True:
self.detector.process(self.read_chunk())
if self.detector.event_finished:
break
return self.detector.get_event_data()
def stream_power_and_pitch_to_stdout(self, data):
"""Call for every chunk to create a primitive stream plot of power and pitch to stdout
Pitch is indicated with 'o' bars, amplitude is indicated with '-'
"""
power = calc_power(data)
bars = "-"*int(1000*power/2**16)
print("%05d %s" % (power, bars))
w = np.fft.fft(data)
freqs = np.fft.fftfreq(len(data))
peak = abs(freqs[np.argmax(w)] * RATE)
bars="o"*int(3000*peak/2**16)
print("%05d %s" % (peak, bars))
class Detector(object):
def __init__(self, background_std, background, start_thresh, end_thresh, num_consecutive,
seconds, dt, quiet=False):
"""Manages the detection of events
Parameters
==========
background_std : float
The standard deviation of the background noise.
background : float
The mean of the background noise.
start_thresh : float
The number of standard deviations above the background noise that the power must exceed
for a data point to be considered as the start of an event.
end_thresh : float
The number of standard deviations above the background noise that the power dip below
for a data point to be considered as the end of an event.
num_consecutive : int
The number of frames needed that must consecutively be above the threshold to be
considered the start of an event.
seconds : float
The number of seconds that must pass after the `end_thresh` condition is met in order
for the event to end. If, during this time, the `start_thresh` condition is met, the
ending of the event will be cancelled.
dt : float
The inverse sampling frequency, i.e the time captured by each frame.
quiet : bool
If True, nothing is sent to stdout
"""
self.quiet = quiet
self.dt = dt
self.bg_std = background_std
self.bg_mean = background
self.seconds = seconds
self.num_consecutive = num_consecutive
# Recast the start and end thresholds in terms of power values
self.start_thresh = self.bg_mean + start_thresh*self.bg_std
self.end_thresh = self.bg_mean + end_thresh*self.bg_std
self.reset()
def update_event_states(self, power):
"""Update event states based on their current states plus the power of the current frame"""
if self.event_started:
self.event_started = False
if self.in_event:
if self.in_off_transition:
if self.off_time > self.seconds:
self.in_event = False
self.in_off_transition = False
self.event_finished = True
elif power > self.start_thresh:
self.in_off_transition = False
else:
self.off_time += self.dt
else:
if power < self.end_thresh:
self.in_off_transition = True
self.off_time = 0
else:
pass
else:
if self.in_on_transition:
# Not in event
if self.on_counter >= self.num_consecutive:
self.in_event = True
self.in_on_transition = False
self.event_started = True
elif power > self.start_thresh:
self.on_counter += 1
else:
self.in_on_transition = False
self.frames = []
else:
if power > self.start_thresh:
self.in_on_transition = True
self.on_counter = 0
else:
# Silence
pass
def print_to_stdout(self):
"""Prints to standard out to create a text-based stream of event detection"""
if self.quiet:
return
if self.in_event:
if self.in_off_transition:
msg = ' o '
else:
msg = ' |||'
else:
if self.in_on_transition:
msg = ' | '
else:
msg = ''
if self.event_started:
msg = '####### EVENT START #########'
elif self.event_finished:
msg = '####### EVENT END #########'
print(msg)
def reset(self):
"""Reset event states and storage buffer"""
self.in_event = False
self.in_off_transition = False
self.in_on_transition = False
self.event_finished = False
self.event_started = False
self.frames = []
def append_to_buffer(self, data):
if self.in_event or self.in_on_transition:
self.frames.append(data)
def process(self, data):
"""Takes in data and updates event transition variables if need be"""
# Calculate power of frame
power = calc_power(data)
self.update_event_states(power)
# Write to stdout if not self.quiet
self.print_to_stdout()
# Append to buffer
self.append_to_buffer(data)
def get_event_data(self):
return np.concatenate(self.frames)
if __name__ == '__main__':
s = Monitor()
s.setup()
Using this code is as easy as saving this file to a script and running it. It works out of the
box. You can process the audio any way you want by changing the contents of wait_for_events.
Storing the data
Detecting events is merely one side of the coin. Equally important is storing the data for
downstream analyses. When deciding on a storage structure, always start simple. So first I
considered storing everything in a simple tab-delimited file, which would have sufficed if I only
wanted to store basic knowledge like when the event happened, how long it lasted, and how loud it
was. Maybe even for some more sophisticated stuff like what frequency ranges it dominated, what
class it belonged to, etc. But instead, I uncompromisingly wanted to retain as much of the raw data
as possible, so it was important for me to store the audio itself. This way I’m guaranteed not to be
bottlenecked by an incomplete data storage when I inevitably come up with interesting ways to
analyze data that would require going back to the raw audio. So to me, it made sense to store
everything in a database. I have familiarity with SQLite, so I
wrote a bare-bones Python class to interface with SQLite that’s based off of the db module of
another repo I contribute to, anvio. It
supports basic reading and writing of data, as well as playing back stored audio. You can check it
out
here.
Here is a demo of the database features:
In summary,
- A database is created for each session.
- Each database has a
selftable and aneventstable - The
selftable that contains administrative info like when the session started, which microphone was used, and all free parameters like the event threshold parameters $X$, $Y$, etc. - Each row of the
eventstable contains all of the info pertaining to an individual event.
Here is an example events table:
| event_id | t_start | t_end | t_len | energy | power | pressure_mean | pressure_sum | class | audio |
| 0 | 2020-08-14 19:33:52.590223 | 2020-08-14 19:33:53.518187 | 0.927964 | 0.23233255845044 | 0.250368072953735 | 0.0013950959289966 | 0.0012945987986554 | � | |
| 1 | 2020-08-14 19:33:59.424781 | 2020-08-14 19:33:59.797081 | 0.3723 | 0.0124660974593919 | 0.0334840114407519 | 0.000334789915565585 | 0.000124642285565067 | � | |
| 2 | 2020-08-14 19:34:16.613249 | 2020-08-14 19:34:17.313352 | 0.700103 | 0.0726653914778307 | 0.103792429796517 | 0.000341944134424603 | 0.000239396114343068 | � | |
| 3 | 2020-08-14 19:34:17.788128 | 2020-08-14 19:34:18.161044 | 0.372916 | 0.0286456558738386 | 0.0768153039125127 | 0.000415586707439386 | 0.000154978932591466 | � | |
| 4 | 2020-08-14 19:34:34.419520 | 2020-08-14 19:34:34.792764 | 0.373244 | 0.0736813904700202 | 0.197408104269647 | 0.000704391482153759 | 0.000262909894364998 | � | |
| 5 | 2020-08-14 19:34:40.413646 | 2020-08-14 19:34:40.970223 | 0.556577 | 0.147239283014793 | 0.264544318243106 | 0.000939155610160731 | 0.000522712412036429 | � | |
| 6 | 2020-08-14 19:34:41.438835 | 2020-08-14 19:34:42.090197 | 0.651362 | 0.341081074757945 | 0.523642881773799 | 0.00178524750772019 | 0.00116284238712364 | � | |
| 7 | 2020-08-14 19:34:59.914203 | 2020-08-14 19:35:02.610606 | 2.696403 | 8.75341461582365 | 3.24633024656316 | 0.00410196267867266 | 0.011060544472661 | � | |
| 8 | 2020-08-14 19:35:09.355492 | 2020-08-14 19:35:11.909793 | 2.554301 | 2670.53404983006 | 1045.50483667746 | 0.0609668444851899 | 0.155727671835365 | � | |
| 9 | 2020-08-14 19:35:15.349941 | 2020-08-14 19:35:15.723554 | 0.373613 | 0.0930470076768425 | 0.24904649376987 | 0.000803286108113117 | 0.000300118132710466 | � | |
| 10 | 2020-08-14 19:35:22.231554 | 2020-08-14 19:35:24.185004 | 1.95345 | 4224.9895692335 | 2162.83476374286 | 0.108183158167411 | 0.21133039032213 | � | |
| 11 | 2020-08-14 19:35:25.261638 | 2020-08-14 19:35:27.487578 | 2.22594 | 6242.85853608116 | 2804.59425504783 | 0.139811369221431 | 0.311211719204751 | � | |
| 12 | 2020-08-14 19:35:29.078094 | 2020-08-14 19:35:30.798650 | 1.720556 | 4640.45106447108 | 2697.06482350535 | 0.13138258673385 | 0.226051097900447 | � | |
| 13 | 2020-08-14 19:35:34.001482 | 2020-08-14 19:35:42.686516 | 8.685034 | 4513.27087836138 | 519.660703499996 | 0.0301028059471401 | 0.261443893146314 | � | |
| 14 | 2020-08-14 19:35:52.047493 | 2020-08-14 19:35:52.419169 | 0.371676 | 0.0484807744715422 | 0.130438270083466 | 0.000595550670187947 | 0.000221351890892775 | � | |
| 15 | 2020-08-14 19:36:08.757406 | 2020-08-14 19:36:10.665634 | 1.908228 | 4241.5389432906 | 2222.76318306335 | 0.11528165374789 | 0.219983679568028 | � |
event_idis the unique ID of the event, and increases chronologically.t_startis the datetime of the event’s start.t_endis the datetime of the event’s end.t_lenis the duration of the event in seconds.energyis the signal energy, i.e. the sum of squared signal $ \sum_{i}^{n} S_i(t)^2 $, where $ S(t) $ is the audio signal. This value increases the louder the event is, or the longer the event lasts. Through my experience it does not seem to scale proportionally with human-perceived “loudness”. (Side note: I wanted to be able to say how many decibels each event was, but this is extremely difficult to pin down without detailed knowledge of the microphone’s physics and circuitry).poweris theenergydivided by thet_len, i.e. power is the time derivative of energy.pressure_meanis a quantity I feel scales proportionally better with human-perceived loudness. It is defined as $ \sum_{i}^{n} |S_i(t)|/n $.pressure_sumis just likepressure_mean, except it is not normalized by the length of the event. It is defined as $ \sum_{i}^{n} | S_i(t) | $.classmerely symbolizes my aspirations of one day classifying the events. For example as bark, “whine”, “dig”, “howl”, etc. For now, it is blank.audiois a gzipped binary object of the numpy array that represents the audio. The compression and decompression is carried out by these two functions:
import gzip
import numpy as np
def convert_array_to_blob(array):
return gzip.compress(memoryview(array), compresslevel=1)
def convert_blob_to_array(blob, dtype=maple.ARRAY_DTYPE):
return np.frombuffer(gzip.decompress(blob), dtype=dtype)
Dog monitoring trial #1
With both event detection and event storage solved, it’s time for the first trial: leaving Maple in the confines of her cage and monitoring what happens. Here she is in the crate just moments before her worst fear is realized: abandonment (for 30 whole minutes).

About 10-feet away lies a Fifine K669B USB microphone I picked up for this project. After double checking everything, I start the application:
./main.py run
… and then quietly leave the apartment.

Results
Fast forward 30 minutes, I’m back with at the apartment with 39MB of data. At first I just wanted to visualize on a line where all the events took place with something I’m familiar with, like matplotlib or seaborn, but after a quick Google search, before I knew it I was learning the basics of Plotly, which can be used to make interactive plots. I’m super glad I spent the time because now I can view an interactive plot for each session. The plot shows up in your browser after typing
./main.py analyze
By default it will pick the last session, but you can pick any session by first listing saved sessions:
./main.py analyze --list
and then choosing a specific session, like:
./main.py analyze --session 2020_08_19_16_45_18
Doing so, yields this:
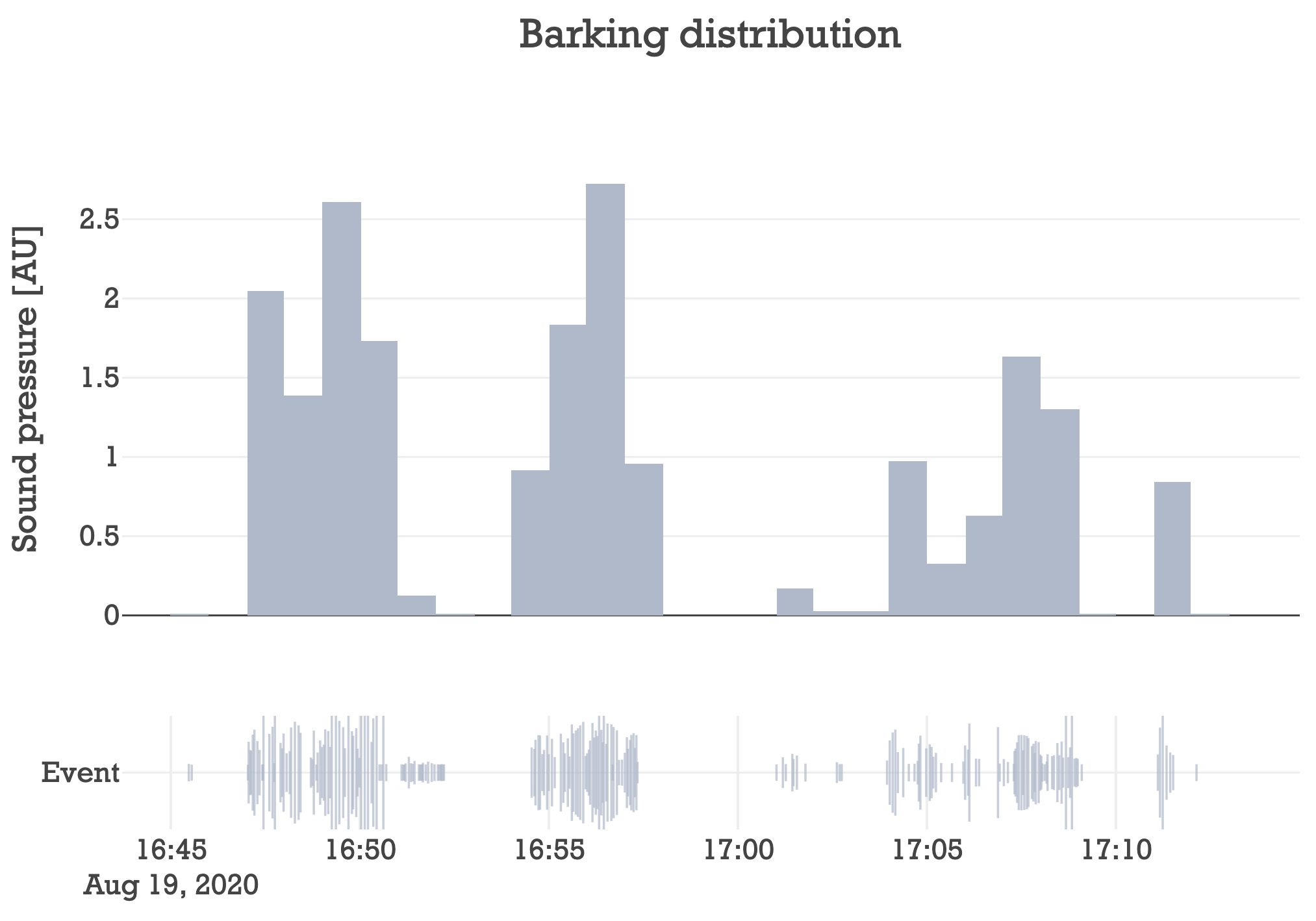
The top plot shows how loud Maple was each minute. And the bottom shows
each individual event as a vertical line, where the line’s length reflects how loud the event was
(pressure_sum). The most striking thing is that Maple has outbursts followed by periods of
silence. In this trial it seems like she has 3 main outbursts:

Each outburst is composed of whines, howls, and barks. Most common is her whine:
Audio files are shrill–turn your volume down.
“i not liking this” - Maple
Then, of course, her coveted howl:
“they forgot me and i need to call them back” - Maple
And finally, her ear-piercing bark (trademarked):
“i frantic and need to get out of this cage so I can find them” - Maple
Uncaptured in this trial, it is known that Maple is capable of yet another form of self-expression, in which she gnaws at the bars of her cage while grunting and foaming at the mouth. This is her most anxiety-ridden behavior and I was happy to see she didn’t do it–hopefully it is a sign she’s already progressed even before I had a chance to acquire data.
Adding owner responses
Missing from the first trial is any mechanism in which the program can “intervene”, either by praising or scolding based on Maple’s behavior. Since Maple, like most other dogs, is very treat motivated, I think it would be excellent to create a treat dispenser that gives Maple treats when she’s quiet. Figuring out the details of that is currently in the works. Until then, I decided that it would be interesting to try and influence her behavior by playing pre-recorded audio of Kourtney and I either praising or scolding her based on the current state of her behavior.
This venture was broken up into two parts: (1) creating something that can record the dog owner’s voice and (2) deciding if and when to intervene.
Recording voices
At first I thought, “I’ll just record a stream of audio in QuickTime player where I praise and
scold Maple, chop it up into individual audio clips using Logic Pro X, and then move them into
a folder that the application expects to find such audio”. But remember when I was talking about
non-committal code being flexible? I realized my codebase already does what I
want: it records and clips audio events. This specifically happens in a class called Monitor.
The class is big, so I won’t paste it here, but one can interact with the class in the following
way.
monitor = Monitor()
event_audio = monitor.wait_for_event()
Calling the wait_for_event method of Monitor will wait patiently until the start of an event is
detected. Then it will record the audio until the event ends according to the “event detection
criteria” discussed already. After the event ends, it returns the audio, which in the above code is
captured by the variable event_audio. So to harness this pre-existing functionality, I simply
created another class called RecordOwnerVoice, which inherits Monitor. RecordOwnerVoice, you
guessed it, records the owner’s voice, and it does it by asking a series of questions through a very
simple command line interface (CLI). By inheriting Monitor, I didn’t have to write a single line of
code related to recording audio. In fact, almost all the code in RecordOwnerVoice pertains to
management of the CLI menu logic:
class RecordOwnerVoice(events.Monitor):
"""Record and store audio clips to yell at your dog"""
def __init__(self, args=argparse.Namespace(quiet=True)):
events.Monitor.__init__(self, args)
self.menu = {
'home': {
'msg': 'Press [r] to record a new sound, Press [q] to quit. Response: ',
'function': self.menu_handle,
},
'review': {
'msg': 'Recording finished. [l] to listen, [r] to retry, [k] to keep. Press [q] to quit. Response: ',
'function': self.review_handle
},
'name': {
'msg': 'Great! type a name for your audio file (just a name, no extension). Response: ',
'function': self.name_handle
},
'sentiment': {
'msg': 'Final question. Choose the sentiment: [g] for good, [b] for bad, [w] for warn. Press [q] to quit. Response: ',
'function': self.sentiment_handle
},
}
self.state = 'home'
self.recording = None
self.recs = OwnerRecordings()
print(f"You have {self.recs.num} recordings.")
def run(self):
self.setup()
while True:
self.menu[self.state]['function'](input(self.menu[self.state]['msg']))
print()
if self.state == 'done':
print('Bye.')
break
def menu_handle(self, response):
if response == 'r':
print('Listening for voice input...')
self.recording = self.wait_for_event()
self.state = 'review'
elif response == 'q':
self.state = 'done'
else:
print('invalid input')
def review_handle(self, response):
if response == 'l':
print('Played recording...')
print(self.recording.dtype)
self.recording = audio.denoise(self.recording, self.background_audio)
self.recording = audio.bandpass(self.recording, 150, 20000)
sd.play(self.recording, blocking=True)
elif response == 'r':
print('Listening for voice input...')
self.recording = self.wait_for_event()
elif response == 'k':
self.state = 'name'
elif response == 'q':
self.state = 'done'
else:
print('invalid input')
def name_handle(self, response):
if response == '':
print('Try again.')
elif ' ' in response:
print('No spaces are allowed. Try again.')
elif response == 'q':
self.state = 'done'
else:
self.name = response
self.state = 'sentiment'
def sentiment_handle(self, response):
if response == 'w':
sentiment = 'warn'
elif response == 'g':
sentiment = 'good'
elif response == 'b':
sentiment = 'bad'
elif response == 'q':
self.state = 'done'
else:
print('invalid input')
return
self.recs.write(self.name, self.recording, maple.RATE, sentiment)
print('Stored voice input...')
print(f"You now have {self.recs.num} recordings.")
self.state = 'home'
Here is a demo of it in action:
Decision logic
Now I’ve got 30 recordings of Kourtney and I either praising or scolding Maple. Here is an example of a praise:
And here is a scold:
The next thing to do is figure out when these should be sprinkled in based on Maple’s behavior. This is an endless hole, and in the interest of keeping things pragmatic, I wanted to develop the most simple heuristics possible that got the job done.
Praise
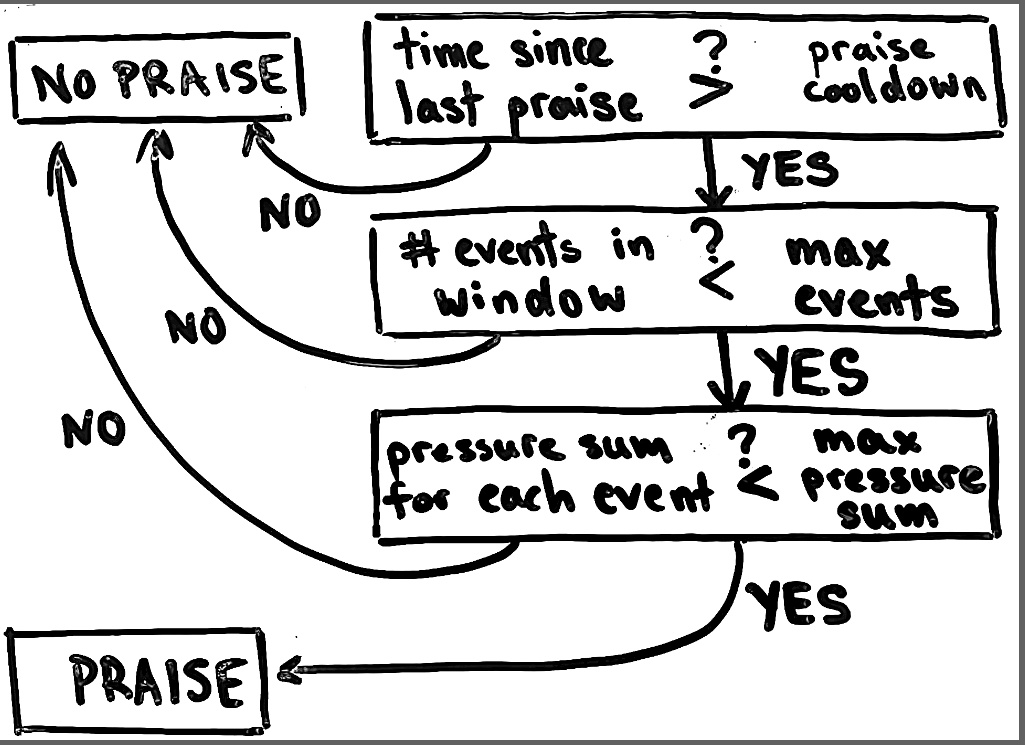
First up, when to praise… To get a sense of things, I studied the interactive plots and decided upon 4 parameters for praising:
praise_response_windowis how big of a time window should be looked at when considering to praise. I chose a default of 2 minutes.praise_max_eventsis the maximum number of events that can be withinpraise_response_windowin order to consider praising. In other words, too many events equals no praise. I chose a default of 10.praise_max_pressure_sumsets a threshold for the loudest that any given event inpraise_response_windowcan be in order to consider praising. If any event has apressure_sum(read: loudness) above this value, no praise for you. I chose a default of 0.15, but the magnitude is arbitrary and depends on the microphone, its placement, and its settings. To keep it consistent, I place the microphone in the same place each time and keep all settings consistent.praise_cooldownis how much time has passed since the last praise to in order consider praising. I chose a default of 2 minutes. This prevents rapid-fire praising.
Together, these criteria create the following flowchart, which is processed after each event, or every 10 seconds (which happens first):
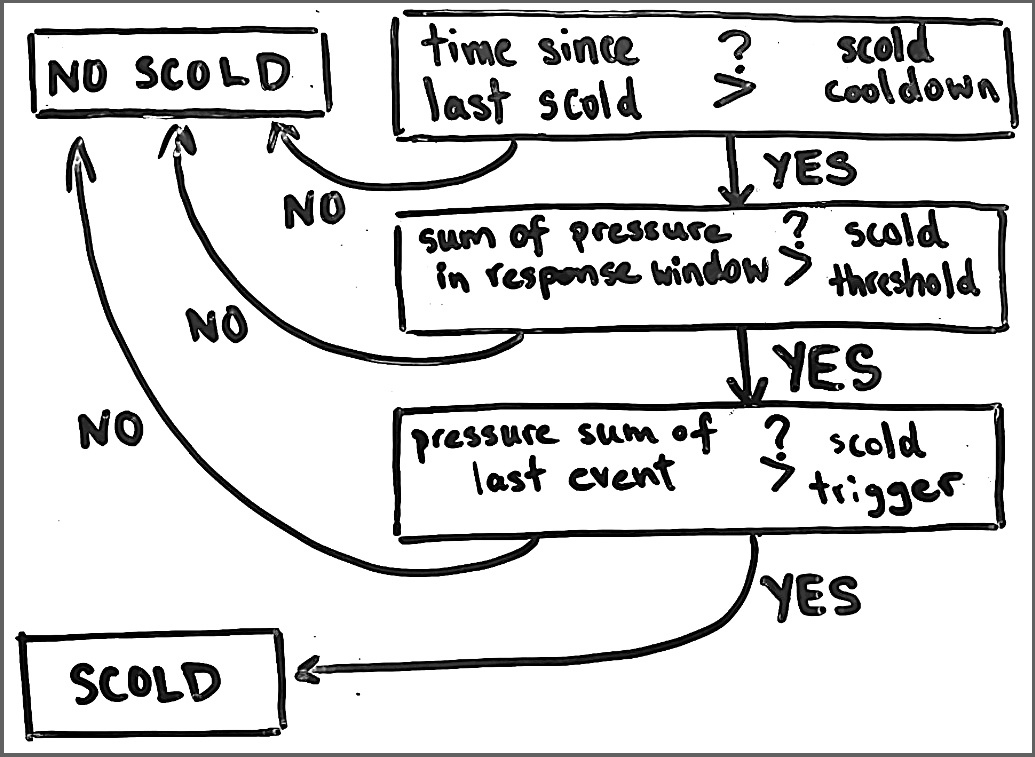
Scold
Next, we have scolding. I decided to use these 4 parameters for scolding:
scold_response_windowis how big of a time window should be looked at when considering to scold. I chose a default of 1 minute.scold_thresholdsets a threshold for whether or not enough noise has been made withinscold_response_windowto consider scolding. If the sum ofpressure_sumvalues for all events withinscold_response_windowexceeds this value, the threshold is passed and scolding is considered. I chose a default of 1.8. For context, in the first trial you can see this was satisfied 4 times.scold_triggerdefines how loud the triggering event has to be in order to be in order to scold. If thepressure_sumof the last event exceeds this value, and thescold_thresholdis also met, Maple will be scolded. This is to ensure that she is scolded immediately after an especially loud sound, rather than after a wimper. I chose a default value of 0.15.scold_cooldownis how much time has passed since the last scold to in order consider scolding. I chose a default of 3 minutes. This prevents rapid-fire scolding.
Together, these criteria create the following flowchart, which is processed after each event:
Implementation
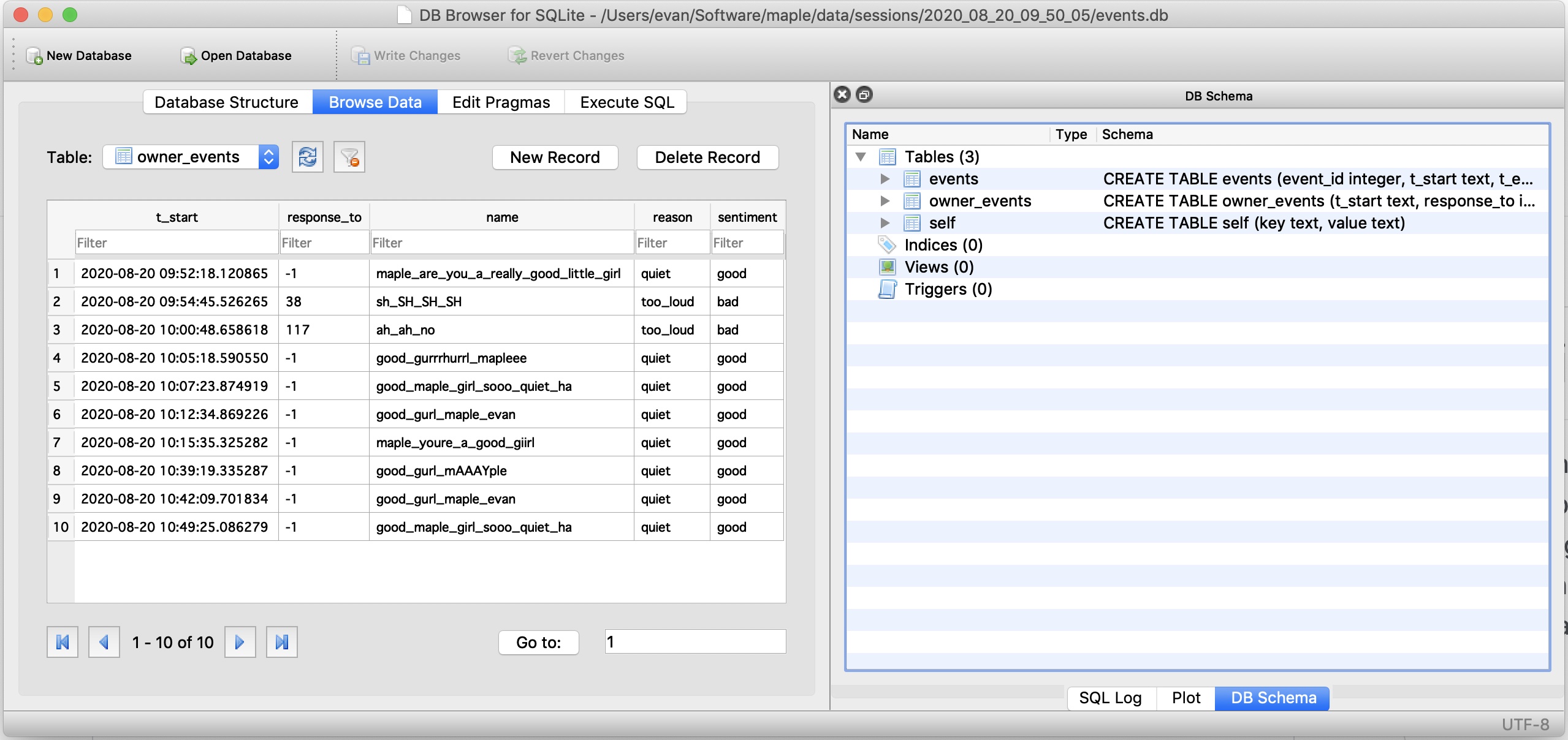
I implemented the decision logic for praising and scolding. If the program decides to respond, a clip with the appropriate sentiment is randomly chosen and played. To store these “owner” events, I added an additional table to the session databases that includes all of the owner response data:
Save the headache, consolidate your tunables
By this point in the project, I have a lot of tunable variables, and so I wanted to consolidate them
in one place. To do this, I created a YAML file called config that contains all of my tunable
parameters. It looks like this:
[general]
# microphone
microphone = Built-in Microphone
# Recalibrate after this many minutes has passed
recalibration_rate = 10000
# Store events into DB whenever this many dog events occur. No reason to set this lower than 100
max_buffer_size = 100
[respond]
# Should there be owner responses? If 0, all other parameters in this section are irrelevant
should_respond = 1
# Should the owner praise?
praise = 1
# The timeframe when considering if to praise (minutes)
praise_response_window = 2
# The max number of events that should be within timeframe to consider praising
praise_max_events = 10
# The maximum pressure sum of any individual event in the timeframe to consider praising
praise_max_pressure_sum = 0.01
# After praising, wait this many minutes to consider praising again.
praise_cooldown = 2
# Should the owner scold?
scold = 0
# The timeframe when considering if to scold (minutes)
scold_response_window = 1.0
# The sum of pressure sums in timeframe to consider scolding
scold_threshold = 1.8
# The pressure sum of the event required to trigger scolding
scold_trigger = 0.15
# After scolding, wait this many minutes to consider scolding again.
scold_cooldown = 3
[calibration]
# The length of the audio in seconds that is used to calibrate
calibration_time = 3
# The standard deviation divided by the mean of the audio signal must be less than this value to be considered calibrated
calibration_threshold = 0.3
# After this many failed attemps, the calibration_threshold will be increased by 0.1 and the process is repeated.
calibration_tries = 4
[detector]
# Standard deviations above background noise to consider start an event
event_start_threshold = 4
# The number of chunks in a row that must exceed event_start_threshold in order to start an event
num_consecutive = 4
# Standard deviations above background noise to end an event
event_end_threshold = 4
# The number of seconds after a chunk dips below event_end_threshold that must pass for the event to
# end. If during this period a chunk exceeds event_start_threshold, the event is sustained
seconds = 0.25
# If an event lasts longer than this many seconds, everything is recalibrated
hang_time = 20
[analysis]
# how many seconds should each bin be
bin_size = 60
To keep things organized, they are placed under section headings like [general], [analysis],
etc. To make these parameters readily accessible in my multi-file project, I added the following to
the module’s __init__.py:
import configparser
import ast
# Load up the configuration file, store as nested dictionary `config`
config_path = Path(__file__).parent.parent / 'config'
config_obj = configparser.ConfigParser()
config_obj.read(config_path)
config = {}
for section in config_obj.sections():
config[section] = {}
for k, v in config_obj[section].items():
try:
config[section][k] = ast.literal_eval(v)
except:
config[section][k] = v
configparser is in the built-in library and parses config, and ast tries its best to interpret
the parameter values as either strings, integers, or floats. By putting this in the __init__.py
file, whenever maple is imported, parameters in config are immediately accessible:
>>> import maple
>>> maple.config
{'general': {'microphone': 'Built-in Microphone', 'recalibration_rate': 10000, 'max_buffer_size':
100}, 'respond': {'should_respond': 1, 'praise': 1, 'praise_response_window': 2,
'praise_max_events': 10, 'praise_max_pressure_sum': 0.01, 'praise_cooldown': 2, 'scold': 0,
'scold_response_window': 1.0, 'scold_threshold': 1.8, 'scold_trigger': 0.15, 'scold_cooldown': 3,
'warn': 0, 'warn_response_window': 0.25, 'warn_cooldown': 1}, 'calibration': {'calibration_time': 3,
'calibration_threshold': 0.3, 'calibration_tries': 4}, 'detector': {'event_start_threshold': 4,
'num_consecutive': 4, 'event_end_threshold': 4, 'seconds': 0.25, 'hang_time': 20}, 'analysis':
{'bin_size': 60}}
Consolidating your variables into an easy-to-access location is essential.
Trial #2
With what is hopefully a properly implemented praise/scold framework, I decided it was time for trial #2. The intention of this trial is to do as I did previously, except this time Maple will be scolded and/or praised based on the decision logic outlined above.
Will praising help quiet her down, or will it initiate outbreaks? Will scolding curb an outbreak or aggravate her? I was so excited to find out.
I set up the speaker and placed it near her. I made sure the praises were soft and soothing while the scold clips were loud and assertive while not being scary loud. When I was happy, I started the run and left the apartment.
One hour after Maple’s least favorite pastime, here are the results:
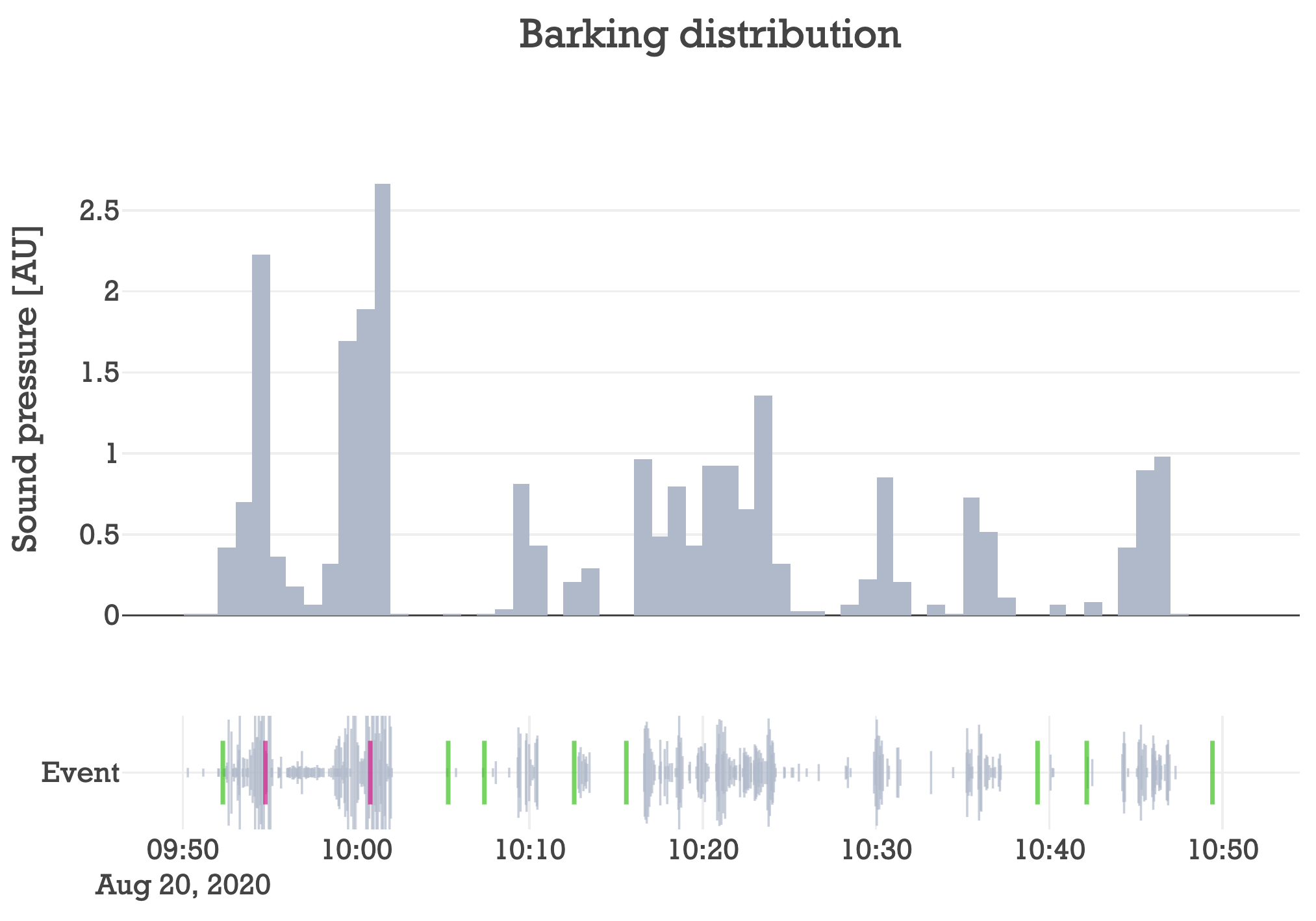
The plot is just as before, except scolds (red) and praises (green) have been overlaid in the bottom plot. Within the first 15 minutes, Maple clearly has two very loud outbursts. To my delight as a programmer, Maple was indeed scolded during these two outbursts. But unfortunately, it seems like scolding if anything only aggravated her. I am also happy to see that praises occur during periods of silence.
Although this data is too anecdotal to say whether or not scolding/praising really makes a difference, it at least verifies that the decision logic for praising and scolding makes sense, and I’m not totally off base. But to really do some interesting stuff, I’m going to need a lot more data…
A longitudinal study is underway
So far, I’ve developed a considerable framework for data acquisition and I’m very happy with the infrastructure. Yet at this point there is almost no data to work with, so over the next few months, I plan to measure Maple’s activity level and see how she progresses over time. Once I feel there are enough data, my plan is to analyze how she has (hopefully) improved, and whether or not verbal praising and/or scolding is effective. In the meantime I may begin working on crafting a DIY treat dispenser. Regardless of what happens next, I’ll detail it all in the next blog post of this series, which I’ll link here.
Bye.
